ULIDs and Primary Keys
By Dave Allie
Published Feb 16, 2022 • 11 min read
Published Feb 16, 2022 • 11 min read
When it comes to picking the type for your database’s primary keys, there are a few divided camps. When making this
decision for Visibuild I had to choose between the simplicity of
sequential IDs and the longevity/future benefits of non-sequential IDs. I chose non-sequential IDs to make it easier to
deal with sharding and regional databases in the future. Out of the many flavours of non-sequential IDs I chose ULIDs.
Here’s how I got there.
Let’s start where most people do, with UUIDs.
UUIDs (universally unique identifiers) are 128-bit labels typically represented as a hexadecimal string broken up into
5 sections containing 32 bits, 16 bits, 16 bits, 16 bits, and 48 bits respectively.
Here’s an example:
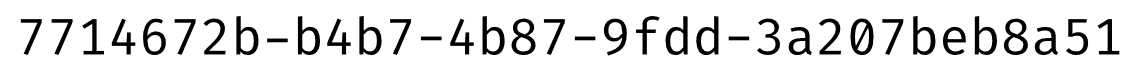
Within the UUID standard (which you can read about in RFC 4122), there
are 5 different versions of that same 128-bit label. The differences between the versions are which inputs are required
to generate the UUID and the structure of the bits that are output.
Version 1 requires knowledge of the computer’s MAC address to generate the label. Version 2 is only guaranteed to be
unique if at most one is generated per computer about every 7 minutes. Versions 3 and 5, are deterministic based on the
supplied input. This leaves only version 4 as a suitable choice for scalable, non-deterministic UUIDs.
When people say UUID they’re almost always referring to UUIDv4. It’s the most prevalent and widely supported UUID
standard, even the example UUID given above is a UUIDv4. As UUIDv4 is based solely on randomness, it is extremely
portable and can be used with very little prior knowledge about the state of the system.
UUIDv4 are composed of 122 bits of randomness, and 6 bits of version/variant identification.

Click the “Regenerate” button to see a few different UUIDv4.
The only non-random sections of a UUDv4 are the version and variant. The version is represented by 4 bits and is always
set to 4 for UUIDv4, you can see it highlighted as the first orange nibble above. The variant is represented by 2 bits
and is set to 2 for the UUIDv4 standard, you can see it highlighted as the second orange nibble above.
The variant is only the first 2 bits of the second highlighted nibble. While the
remaining 2 are random, meaning the value of that nibble can be 8 (
1000), 9 (1001), a (1010),
or b (1011).While there are only 5 UUID variants in the RFC, there’s
a draft that includes 3 new ones:
UUIDv6, UUIDv7, and UUIDv8.
The three new versions are all based on a similar structure of a combination of time bits in the most significant
positions, followed by random bits. The difference between the three is which kind of clock is used to generate the time
bits. Version 7 from the draft is using Unix Epoch time, making it the likely candidate for adoption in the future.
Even within version 7, there are a few different ways to represent the time. Different levels of sub-second precision
can be used, but the more precise in time you get, the fewer random bits you’ll be able to use. Let’s take a look at the
millisecond precision setup of UUIDv7.
With the millisecond precision setup, there are 48 bits of time, 6 bits of version/variant, 12 bits for a
monotonic sequence, and 62 bits of randomness.
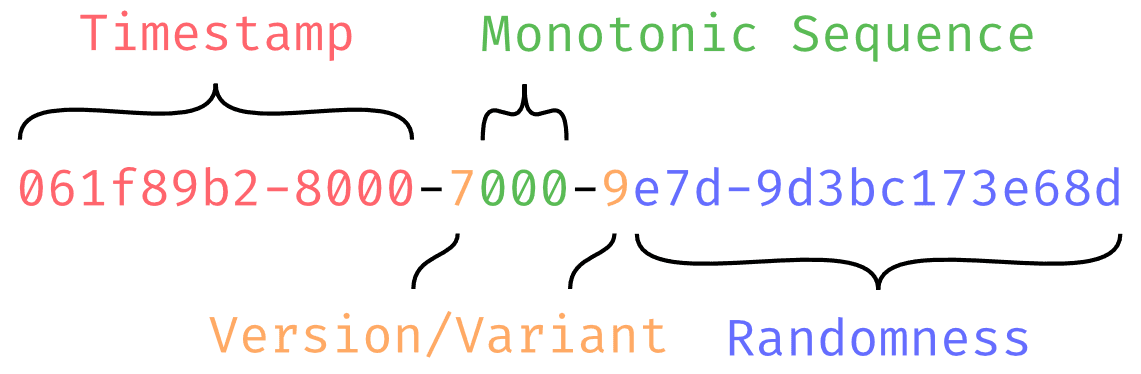
UUIDv7 always dedicates the first 36 bits to the seconds of the timestamp, and then a variable amount of bits for the
sub-second precision, in our case that’s 12 bits for the milliseconds within the second.
If you click “Regenerate” a few times, you should see the first 9 characters of the timestamp only
change once a second, these are the bits representing the Unix Epoch time in seconds. The last three bits are the
milliseconds within that second.
The version and variant follow the same setup as UUIDv4, however the version is set to 7.
The main value for the timestamp at the front of the UUID is that UUIDv7s (and the other new UUIDs in the draft) are
monotonically increasing (within the same sub-second), meaning that a UUIDv7 generated now is always going to be larger
than a UUIDv7 generated a millisecond ago.
You’ll also notice a new kind of section in UUIDv7, the “monotonic sequence” section. This section of 12 bits is
designed to ensure that the UUIDs generated within the same sub-second are also monotonically increasing. In our case,
for each subsequent UUIDv7 generated within the same millisecond, the monotonic sequence counter will increase by one.
Note that this is only relevant for UUIDs generated on the same machine within the same millisecond, it will not ensure
any ordering of UUIDs if they’re generated independently of each other in the same millisecond.
Here are some example UUIDs generated in the same millisecond:
061ff8d8-e24b-7000-8092-ca1e5440d491061ff8d8-e24b-7001-b653-1c41e471cd78061ff8d8-e24b-7002-9bc2-82b5da559f1d
When using UUIDv7 as a primary key, you get the same sortability as a sequential ID with the flexibility of
distributed generation. If you’re looking to do a performant sort on creation time using UUIDv4, you’d need a separate
indexed creation time column, but if you’re using UUIDv7 then you can use the primary key as the sort column (since it’s
already indexed).
In late 2017, almost 4 years before the UUIDv7 specification was drafted, the Universally Unique Lexicographically
Sortable Identifier (or ULID) was proposed, not as an RFC Draft, but as a grassroots proposal over GitHub. You can take
a read of the (quite concise) specification for ULID on GitHub.
A ULID is a 128-bit label, just like a UUID. It’s sortable, has millisecond precision, and is monotonically increasing,
just like UUIDv7.
ULIDs are typically represented as a Crockford’s Base 32 encoded string, instead
of a hexadecimal string like UUIDs. As an example, instead of
017eb31e-1440-b69e-d82f-5f0937f823c8, the same value can
be represented as 0GWWXY2G84DFMRVWQNJ1SRYCMC.For the purpose of comparison with UUIDs, I’m going to represent all ULIDs as hexadecimal strings, in the same 8, 4, 4,
4, 12 segments which we have been using.
Within a ULID, there are 48 bits of time and 80 bits of randomness.
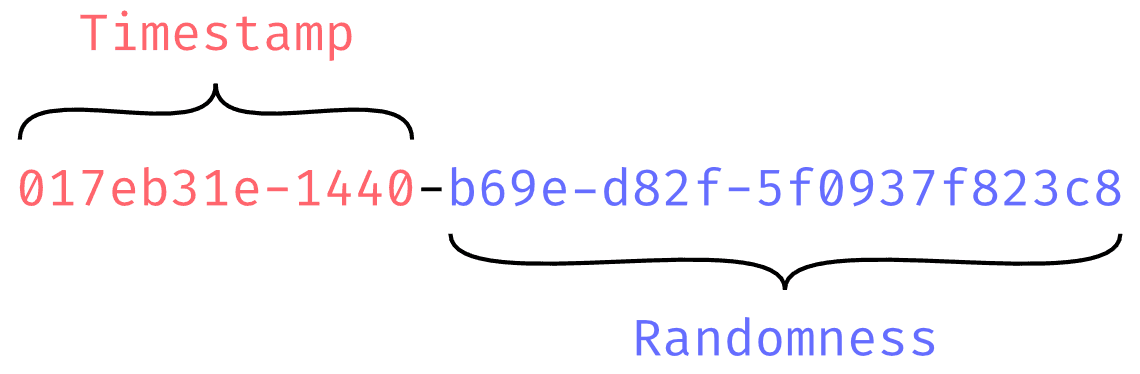
While there are 48 bits of time information in both UUIDv7 (with millisecond precision) and ULID, the ULID standard
encodes the time as Unix Epoch in milliseconds for the whole 48 bits whereas UUIDv7 splits the time into 36 seconds bits
and 12 millisecond bits.
ULIDs also remove the bits pertaining to the version and variant, giving us 6 extra bits to play with but removing all
indication that ULIDs are in fact ULIDs. Because UUIDs encode version and variant information inside the label, they can
be reliably decoded into their composite parts (e.g. timestamp and randomness). If you wanted to extract the timestamp
from a ULID, the client would need to know that the string being processed is a ULID, and not an invalid (or potentially
valid looking) UUID.
ULIDs are monotonically increasing, but there is no defined monotonic counter like in UUIDv7. Instead, ULIDs generated
in the same millisecond on the same machine will have sequential randomness sections.
Here are some example ULIDs generated in the same millisecond:
017ece40-2a1e-63ac-a58d-e336f30c1d76017ece40-2a1e-63ac-a58d-e336f30c1d77017ece40-2a1e-63ac-a58d-e336f30c1d78
ULIDs are a great alternative to UUIDv7s. They contain more randomness and a straightforward structure at the cost of
not explicitly exposing the version, variant, or monotonic counter. ULIDs are also the perfect choice if you’re writing
some apocalypse-scenario software (assuming you have a working computer) as they can continue to be generated until
10,889AD compared to UUIDv7s measly 4,147AD death date.
- UUIDv7
- UUIDv7 will work until 4,147AD whereas ULID will work until 10,889AD
| Format | Sortable | Monotonic | Randomness |
|---|---|---|---|
| UUIDv4 | No | No | 122 bits |
| UUIDv7 | Yes | Yes | 62 bits |
| ULID | Yes | Yes | 80 bits* |
* - Random bits are incremented sequentially within the same millisecond.
This section is tailored to PostgreSQL, if you’re using a different database engine then you’ll
need to look elsewhere to understand how to implement these kinds of primary keys.
While all of these formats can be generated by the client before inserting them into the database, for the purpose of
simplicity and consistency, having them be generated within the database engine is preferred.
Thankfully, PostgreSQL includes a
uuid data type which
accepts a case insensitive 128-bit hexadecimal string, parses it into binary data and stores it as 16 bytes of data. This
is drastically better than storing the value as a string in the database, which would take up 37 bytes of space
including the dashes, or 33 bytes of space with the dashes stripped out.Here are some implementation details for populating those
uuid columns and setting up tables with UUID/ULID primary
keys:PostgreSQL has built in support for UUIDv4 through the
pgcrypto or the uuid-ossp extensions.CREATE EXTENSION IF NOT EXISTS pgcrypto; SELECT gen_random_uuid(); --> f449a5bc-a221-4e9d-8819-e7f22b83d8ae
This makes it extremely easy to setup a table with a UUIDv4 primary key:
CREATE TABLE my_uuidv4_things(
id UUID NOT NULL DEFAULT gen_random_uuid(),
name TEXT NOT NULL,
PRIMARY KEY (id)
);
INSERT INTO my_uuidv4_things(name) VALUES ('foo');
SELECT * FROM my_uuidv4_things;
-- id | name
----------------------------------------+------
-- 8501364b-b669-4c17-bd98-00bad8cd8f7d | foo
There don’t seem to be any existing built-in or extension functions that support generating UUIDv7s in PostgreSQL. To
generate a UUIDv7, the function below could be tweaked in order to support the correct formatting.
There are a few different implementations of ULIDs in Go, or in
plsql. However, both of these implementations return the Crockford Base 32 text
representation of ULID (taking up 26 bytes), instead of as a UUID datatype (taking up 16 bytes). Due to the natural
multiplexing nature of PostgreSQL (and relational databases in general), having a consistent, shared monotonic counter
is difficult, if not impossible. The Go library used by the Go PostgreSQL
implementation includes an implementation of the monotonic counter, however, it’s not used by the Go PostgreSQL
extension. The plsql implementation doesn’t have a monotonic counter at all.
I wanted a simple ULID PostgreSQL implementation without the complexity of the monotonic counter that generated a
UUID data typed value. So I wrote one:
CREATE EXTENSION IF NOT EXISTS pgcrypto; CREATE OR REPLACE FUNCTION generate_ulid() RETURNS uuid AS $$ SELECT (lpad(to_hex(floor(extract(epoch FROM clock_timestamp()) * 1000)::bigint), 12, '0') || encode(gen_random_bytes(10), 'hex'))::uuid; $$ LANGUAGE SQL; SELECT generate_ulid(); --> 017eb31e-1440-b69e-d82f-5f0937f823c8
Breaking down the function:
- The first half
lpad(to_hex(floor(extract(epoch FROM clock_timestamp()) * 1000)::bigint), 12, '0')gets the milliseconds since the Unix Epoch, and converts it to a hexadecimal string of length 12 (it’ll have a leading 0 for the next 500 years or so). - The second half
encode(gen_random_bytes(10), 'hex')generates 10 random bytes and converts them to hexadecimal.
Together these make the 16-byte (or 128-bit) ULID label, which is finally cast to a UUID data type with
::uuid.Our new function can now be used as a default value for a primary key:
CREATE TABLE my_ulid_things(
id UUID NOT NULL DEFAULT generate_ulid(),
name TEXT NOT NULL,
PRIMARY KEY (id)
);
INSERT INTO my_ulid_things(name) VALUES ('foo');
SELECT * FROM my_ulid_things;
-- id | name
----------------------------------------+------
-- 017eb31e-1440-b69e-d82f-5f0937f823c8 | foo
When compared to the native implementation of
gen_random_uuid(), generate_ulid() performs 73% slower when
generating 10 million values, but only 31% slower when generating and inserting 1 million values.Meaning that while ULIDs are slower to generate (at least with this implementation), they are much faster to insert. My
guess is that due to the sequential and highly clustered significant bytes of the ULIDs, they are much faster to create the
index entries for. Meanwhile, the UUIDv4s are extremely sparse, so they are much slower to create the index entries for.
Here’s how I got these numbers:
createdb ulid-test
generate-benchmark.sqlEXPLAIN ANALYSE SELECT gen_random_uuid() FROM generate_series(1, 10000000); -- 6766.681ms EXPLAIN ANALYSE SELECT generate_ulid() FROM generate_series(1, 10000000); -- 11750.966ms
generate-insert-benchmark.sqlCREATE TABLE uuid_keys(id UUID); CREATE TABLE ulid_keys(id UUID); EXPLAIN ANALYSE INSERT INTO uuid_keys(id) SELECT gen_random_uuid() FROM generate_series(1, 1000000); -- 1372.470ms EXPLAIN ANALYSE INSERT INTO ulid_keys(id) SELECT generate_ulid() FROM generate_series(1, 1000000); -- 1803.472ms
ULIDs are slower than their counterparts. For me, the benefits of a sortable globally unique identifier make the
tradeoff worth it.