Grapple - An actual interruptable download accelerator
By Dave Allie
Published Sep 12, 2018 • 5 min read
Published Sep 12, 2018 • 5 min read
A bit ago I needed to pull some large binary files down from a remote server and, at the time, had an extremely spotty
internet connection. After about the 5th attempt to download the file and having my internet drop 15 minutes into the
download, I gave up. Chrome’s download manager wasn’t cutting it, so I opened up GitHub, had a quick look at how other
people were writing download tools, and stumbled across Snatch.
Snatch’s description was “A simple, fast and interruptable download accelerator, written in Rust”. Exactly what I
wanted, and written in a language I was interested in! Not only that, they were also a trending Rust repository at the
time and had almost 600 stars. Taking a closer look at the repository’s readme, that excitement turned to disappointment
pretty quickly.
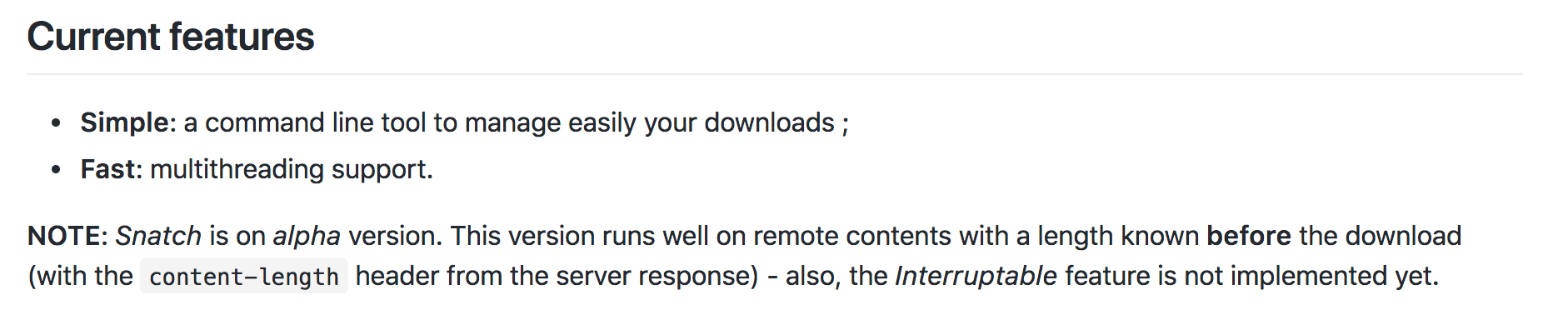
the Interruptable feature is not implemented yet.
What... the... hell...
How can you have an interruptable download accelerator, without the interruptable part?!
I tried to get comfortable with the codebase to see if writing in the interruptable feature would be difficult. I opened
an issue, wrote a PR to fix it, and gave a bit more thought to the feature. I formalised my thoughts for how I believed
the feature should be written and wrote up a draft proposal for it in
the open issue for interruptablilty in the repo.
The way Snatch worked was to first pre-allocate the space needed to download the file. Start
n threads at even
intervals of the file and have each of the threads download its section. If the download was interrupted, there was no
way to determine how much of the file each thread had downloaded so all threads had to start from the beginning of their
section.The changes I proposed to get the feature working were as follows:
- The first 32 bits would be a 32-bit integer that represented the number of 64kB chunks in the file
- Let’s call this number
n - The next
nbits were bit flags representing if the relevant chunk had been downloaded - e.g. For a 256kB file,
0101would mean that the 2nd and 4th chunk had been completely downloaded - The rest of the file would follow.
1 2 3 |-|-------|---------------------| 1: 32-bit number holding the number of 64kb chunks 2: n bits holding bit flags for each chunk 3: File contents
Restarting the download, each thread could look at the bit flags in section 2 and determine if part of the download
could be skipped. When the download was complete, the first 32 bits could be read which would let us know how many bits
in section 2, so we could remove both section 1 and section 2, without touching the file contents.
This approach definitely had a few limitations. As we could only hold state for 232 64kB chunks, it had a
maximum file size limit of 256TB (232 * 64 * 1024 / 10244). Threads would need to download a
range of bytes that both started and finished on a 64kB chunk so that no chunk was downloaded by two separate threads.
There were also a couple of other small caveats that would mean slight modifications to the download and threading
logic.
I was hoping after laying it all out to the author of the project, he would approve of it, and I could forge ahead and
build it. Unfortunately, he didn’t seem too interested in actually having the interruptable feature written, and instead
wanted to polish every little aspect of the download part before considering interruptability.
So naturally, being a developer, I just went off and wrote my own package.
I present Grapple, an actual interruptable download accelerator. I took some
pretty heavy inspiration from Snatch as Grapple was initially intended to be a proof of concept for the feature, but
rapidly eclipsed Snatch’s feature-set.
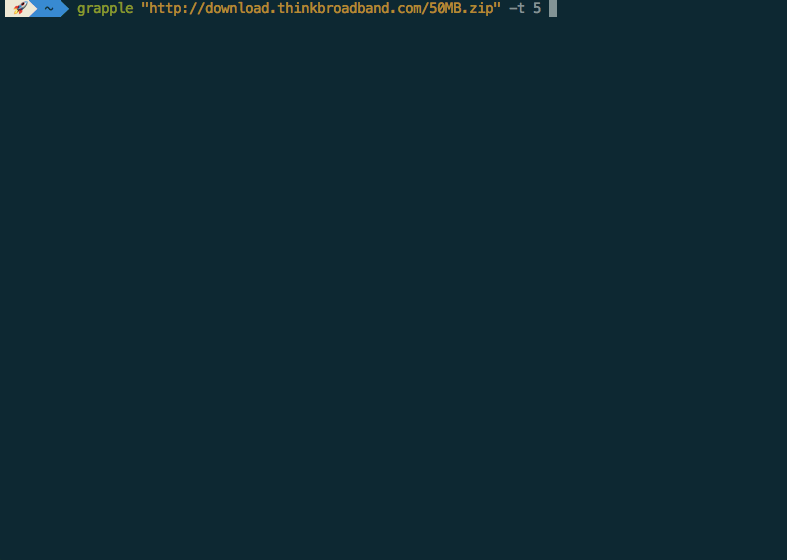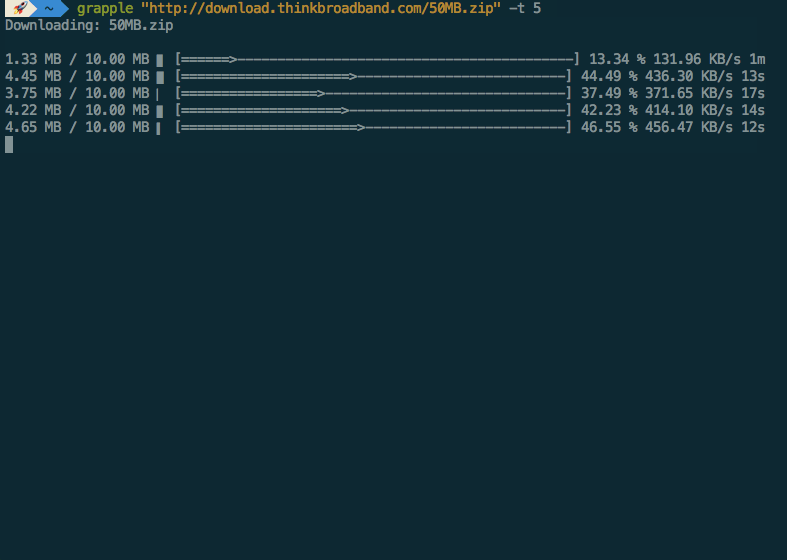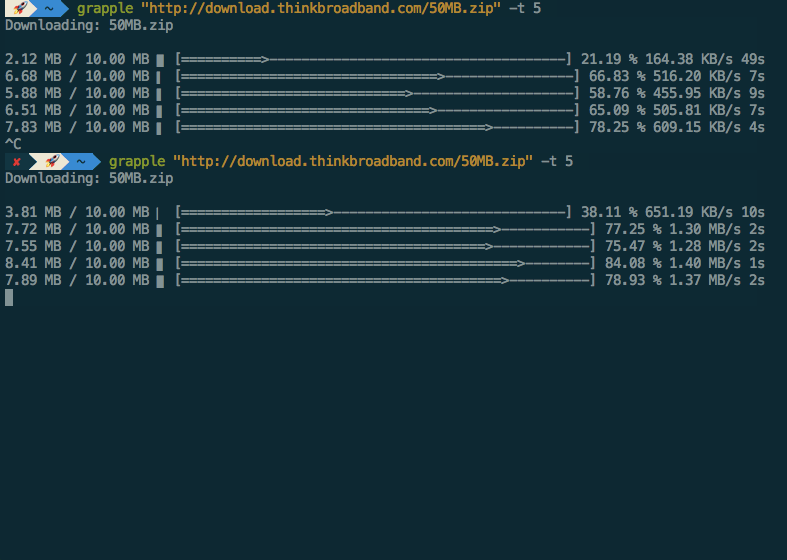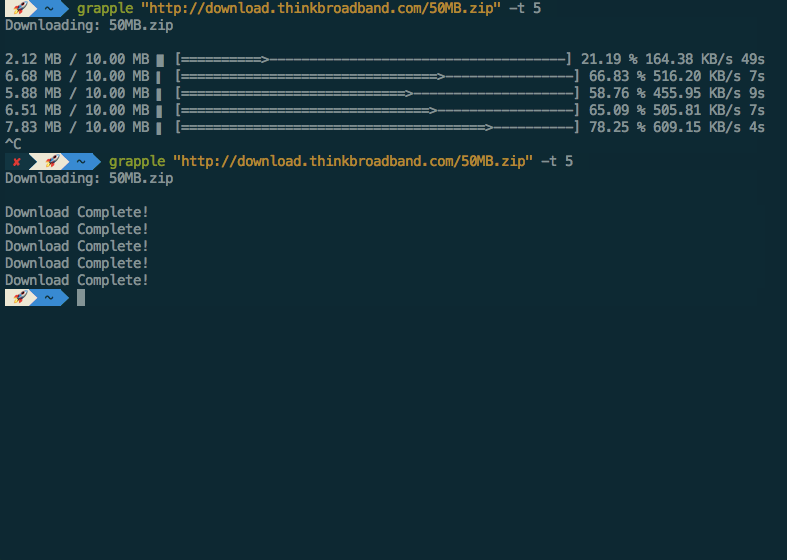
The actual implementation was a little different to what I initially proposed. It turns out it’s really bloody hard to
efficiently remove the first
n bytes of a file. Conversely, it’s really easy to truncate the end of the file, so one
of the changes was to move all the metadata to the end of the file. Also, to drastically increase the file size limit,
I used a 64-bit integer for the number of chunks and increased the chunk size from 64kb to 128kB. This brought the new
file size limit up to 2,147,483,648PB. I’ll probably be dead before files get large.New file layout:
3 2 1 |---------------------|-------|-| 1: 64-bit number holding the number of 128kb chunks 2: n bits holding bit flags for each chunk 3: File contents
I use Grapple about once a week, and it hasn’t crashed on me yet (touch wood). I still go back to it now and again to
make some enhancements, just recently I added bandwidth limiting per thread to prevent saturating my internet connection
and upsetting my housemates. Grapple has definitely been one of the more useful tools I’ve written, and I intend to keep
updating it over time as I need more and more from it.
Just for fun, as I was writing this, I went back to look at Snatch to see if the interruptable feature was implemented
yet. Snatch is deprecated in favour of a fork, Zou, and this was in the readme:
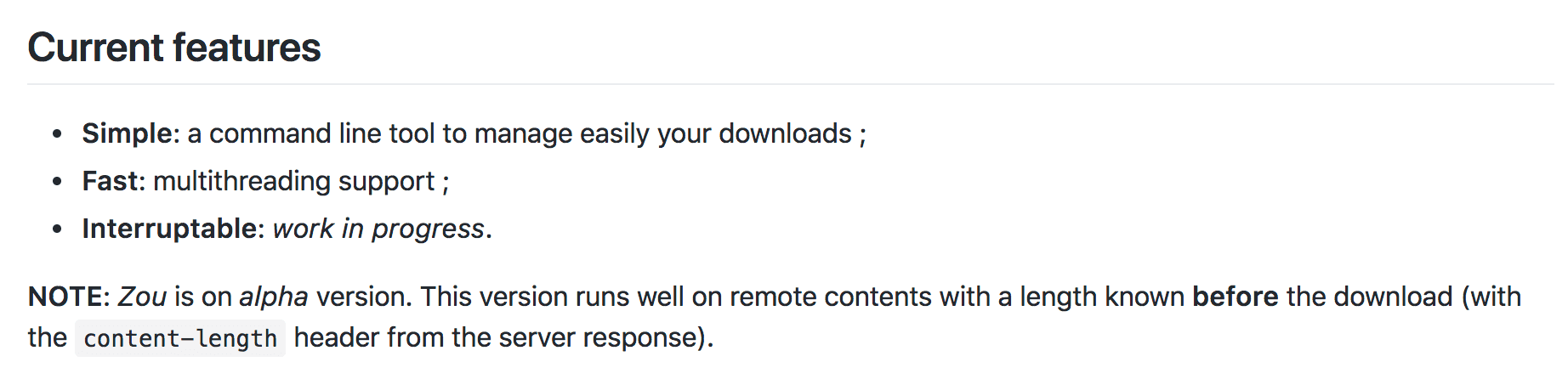
The interruptable feature still isn’t done. I think I’ll just stick to using Grapple.